Before we start analyzing data in Python, it’s important to understand how to design experiments and how to collect data. Experiments are done to see if a treatment has an effect on the outcome, also known as the response. Experiments aim to answer the question: Does something work? In other words, does a specific treatment cause a specific response?
In experiments, the researcher decides who gets the treatment and who does not. The group of subjects who get the treatment are called the treatment group and the group of subjects who do not get the treatment are called the control group. The researchers collect data on the control group to make comparisons between outcomes with the treatment and outcomes without the treatment. If the researcher plays no role in deciding who gets the treatment and who does not, the investigation is called an observational study. For now, we are going to focus on experiments:
When designing experiments, the goal is to make the treatment group and control group as alike as possible. There are many ways to divide the subjects into two groups, however, randomization is best!
Randomly dividing the subjects into the 2 groups is the most likely to make the treatment and control groups as alike as possible because it eliminates human bias. With enough subjects, differences average out. Not only differences that the researcher has identified as relevant, but on all characteristics, including the hidden ones that the researcher might not realize are important.
The ideal experimental design is the randomized controlled double-blind experiment.
Randomized controlled double-blind experiments are the gold standard in the medical field. They are also becoming more commonly used in other fields such as economics. A randomized controlled double-blind experiment must meet three criteria:
If an experiment is designed correctly (randomized, controlled, and double-blind), at the end of the study, any differences in the treatment and control groups can be attributed to the treatment itself. We can trust these studies and more importantly, we can conclude that the treatment did cause the response. This is incredibly powerful!
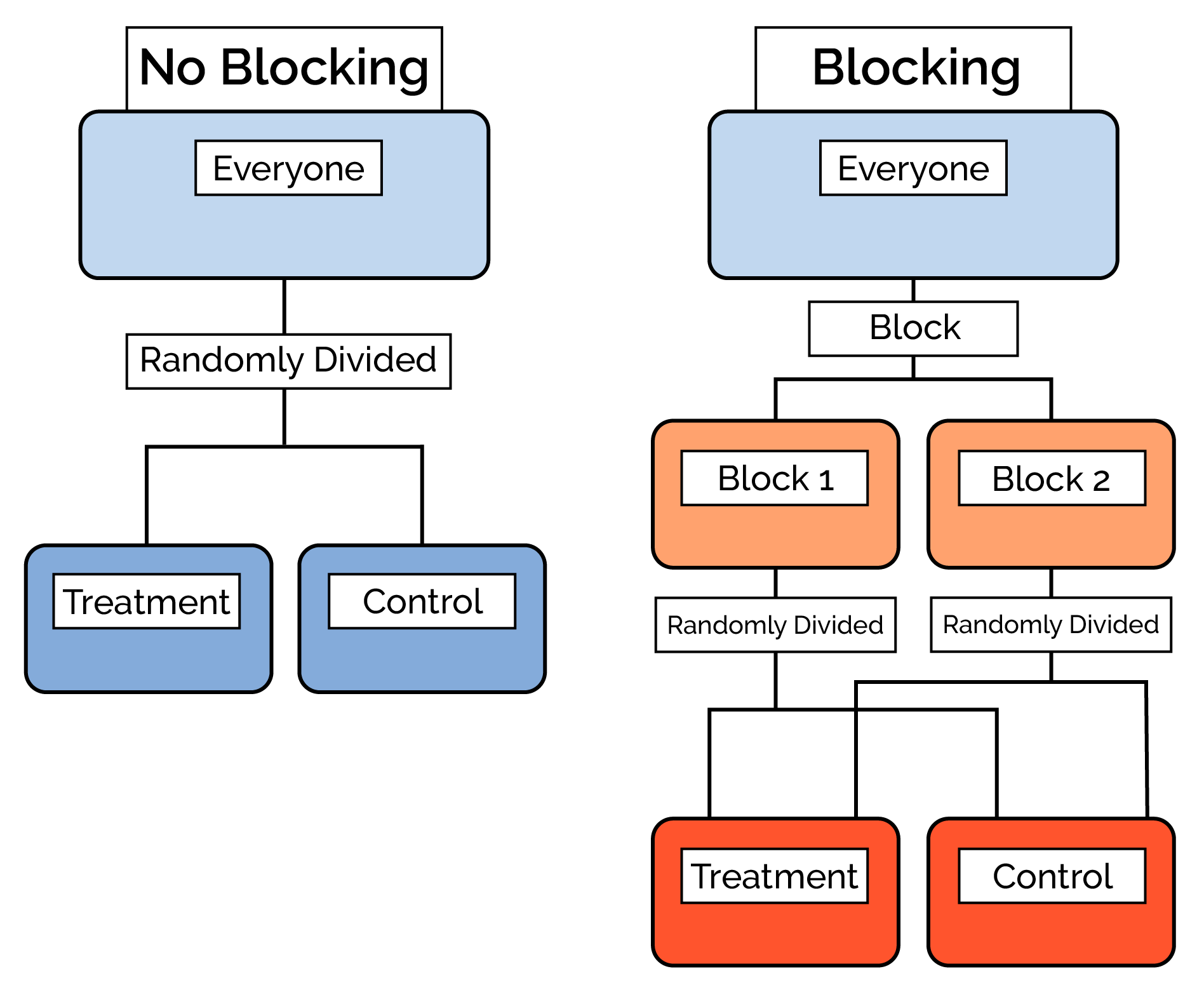
With enough subjects, random differences average out when we randomly divide subjects into a treatment and control group. But what do you do if you have a small sample?
Blocking
With small samples, it's possible to randomly divide the subjects and still get different groups. In order to address this, researchers “block” subjects into relatively homogeneous groups first and then randomly decide within each block who becomes a part of the control group and who becomes a part of the treatment group.
Blocking first, then randomizing ensures that the treatment and control group are balanced with regard to the variables blocked on. If you think a variable could influence the response, you should block on that variable.
Q1: In which situation would blocking be the most necessary? Assume the subjects in the studies are either ‘A’ average or ‘B’ average students and that this variable does affect the response.
A randomized controlled experiment that has 20,000 subjects. An observational study with 50 subjects. A randomized controlled experiment that has 16 subjects, 4 are ‘A’ students and 12 are ‘B’ students. An observational study with 10,000 subjects.
Q2: There are 30 students in a math class and we have a drug that we think can improve their studying abilities. We want to do a randomized controlled experiment to test if this drug works. However, 20 of the students take notes on paper and 10 take notes online. With only 30 students, random assignment could give us large accidental differences between the two groups. How should you block them so that the treatment and control groups are as alike as possible?
Randomly divide the students into two groups first, then separate the paper from the online notetakers. Divide the students based on notetaking preference first, then randomly assign an equal amount of each preference group into treatment and control. Divide the students based on notetaking preference first, then let the students choose if they are put in the treatment or control group. Randomly divide the students into two groups first, then let the students choose if they are put in the treatment or control group.
Q3: Double-blind is best described as:
The treatment and control groups are unaware of which is which, but the researcher knows. The subjects know which group they are in, treatment or control, but the researcher is unaware of who is in what group. Neither the researcher nor the subjects know who is in what group. Only the control group is told what group they are in, the treatment and researcher are unaware of who resides in what group.
Q4: Which of the following is NOT a best practice when designing an experiment?
Double-blind Randomization Controlled Researcher is fully aware of all study components, including which subjects are in the control and which are in the treatment group.
Q5: In some studies it can be obvious who is in the treatment and control groups. For example, if you are testing whether or not a drug works, the individuals in the treatment group will be taking the drug and the individuals in the control group will not be taking the drug. In order to accomplish a double-blind study, researchers often use a placebo so that it’s not obvious who is in which group. A placebo is best defined as:
A sugar pill; it has no medicinal qualities but it simulates taking a drug. No one knows that it is a sugar pill. An elaborate deception where the control group is unaware there is a drug being tested. The same drug the treatment is getting, just a different color. When the treatment and control groups have different researchers and the researchers assigned to the control group are unaware there is a drug being tested.
Data Science Discovery is an open-source data science resource created by The University of Illinois with support from The Discovery Partners Institute, the College of Liberal Arts and Sciences, and The Grainger College of Engineering. The aim is to support basic data science literacy to all through clear, understandable lessons, real-world examples, and support.